Design Consistent Hashing
Explore Consistent Hashing with Virtual Nodes for Key Routing and Allocation
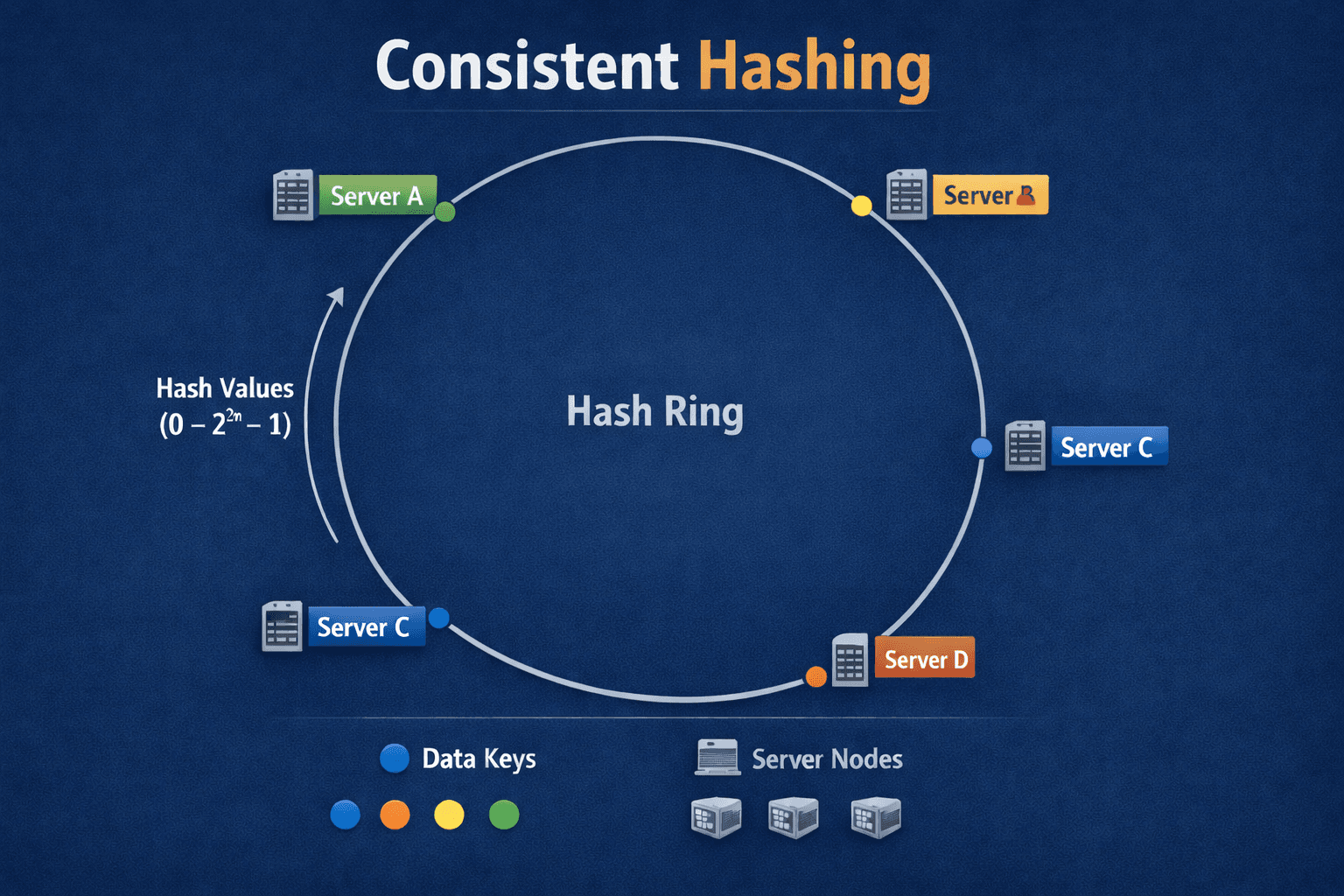
Consistent hashing is a technique in distributed systems that maps data keys and servers to a conceptual "hash ring," minimizing data remapping when nodes are added or removed, ensuring stability and efficient load balancing by only reassigning a fraction of keys, unlike traditional hashing. It works by placing servers and data points on this ring, then assigning data to the next server clockwise, making it ideal for databases (Cassandra), CDNs (Akamai), and distributed caches.
First,
What is key ?
A key is any identifier that:
Uniquely represents a piece of data or request
Needs to be consistently routed to the same node
Can be hashed to produce a number
Why consistent hashing exists?
The problem it solves:
Traditional hashing uses: server = hash(key) % number_of_servers
Example with 4 servers:
hash("user:123") % 4 = 2→ Server 2hash("user:456") % 4 = 1→ Server 1
What breaks:
When you add/remove a server (say go from 4 to 5 servers):
hash("user:123") % 5 = 3→ Now Server 3 (was Server 2!)hash("user:456") % 5 = 1→ Still Server 1 (lucky!)
Result: Almost every key gets remapped to a different server because the modulo divisor changed. If you have 1 million cached items, adding one server means ~800,000+ cache misses and data movement.
Consistent hashing fixes this:
When adding/removing servers, only ~K/N keys need remapping (where K = total keys, N = number of servers).
Add a server: ~1/N keys move
Remove a server: only that server's keys move
Real-world impact:
Without consistent hashing:
Adding a cache server → entire cache invalidated → database meltdown
Server failure → all keys remapped → cascading failures
With consistent hashing:
Adding a cache server → smooth, minimal disruption
Server failure → only affected keys redistributed
Bottom line: It enables elastic scaling in distributed systems without causing massive data shuffles that would overwhelm your infrastructure.
How it works
Hash Ring Creation: A large, circular hash space (the "ring") is defined, using a hash function (like MD5) for both servers and data keys.
Node Placement: Each server (or node) is hashed and placed at a specific point on the ring, often using multiple virtual points for better distribution.
Data Mapping: Data keys are also hashed, placing them on the ring.
Assignment: A data key is assigned to the first server encountered when moving clockwise from the key's position on the ring.
Common enhancement:
Systems often use "virtual nodes"—each physical server gets multiple positions on the ring. This distributes load more evenly and prevents hotspots when servers have different capacities.
Real-world uses:
Distributed caches (Memcached, Redis clusters), distributed databases (Cassandra, DynamoDB), and content delivery networks all use consistent hashing to efficiently distribute data across changing sets of servers.
The problem without virtual nodes:
Imagine you have 3 servers on the hash ring. With simple consistent hashing, each server appears once on the ring at a random position. You might end up with:
Server A: position 100
Server B: position 200
Server C: position 500
This creates uneven ranges:
Server A handles keys from 500→100 (a huge arc of ~600 units)
Server B handles keys from 100→200 (only 100 units)
Server C handles keys from 200→500 (300 units)
Server A gets 6x more load than Server B—very unbalanced!
The solution with virtual nodes:
Instead of placing each server once, you create multiple "virtual" copies. Say 150 virtual nodes per physical server:
Server A: positions 45, 123, 289, 467, 891, ... (150 positions total)
Server B: positions 12, 234, 356, 678, 923, ... (150 positions total)
Server C: positions 78, 145, 401, 567, 834, ... (150 positions total)
Now the ring has 450 points instead of 3, and they're scattered throughout. This means:
Each server's ranges are distributed across the entire ring
Load averages out statistically—each server handles roughly 33% of keys
When a server fails, its load redistributes evenly across remaining servers
How this virtual nodes are placed in ring ?
The placement of virtual nodes uses hash functions to generate their positions on the ring.
For each physical server, you generate multiple virtual node identifiers and hash them:
Server A, Virtual Node 0: hash("ServerA-0") → position 12847
Server A, Virtual Node 1: hash("ServerA-1") → position 98234
Server A, Virtual Node 2: hash("ServerA-2") → position 45621
...
Server A, Virtual Node 149: hash("ServerA-149") → position 73012
Common patterns:
Append index:
hash(serverID + index)- Example:
hash("192.168.1.10-0"),hash("192.168.1.10-1")
- Example:
Random seeds: Use different hash functions or seeds
- Example:
MD5(serverID + vnodeNumber)
- Example:
Multiple hash functions: Apply different hashes to the same server ID
- Example:
SHA1(serverID),MD5(serverID),CRC32(serverID)
- Example:
Key properties:
The hash function produces pseudo-random but deterministic positions
Positions are uniformly distributed across the ring (0 to 2^32 or similar)
Same server always gets the same virtual node positions (deterministic)
Different servers get different positions (good hash distribution)
Data structure:
In practice, you maintain a sorted list or tree of all virtual node positions:
[12847 → Server A, 23456 → Server C, 45621 → Server A, 67890 → Server B, ...]
When a key needs placement, you hash it and do a binary search to find the next position clockwise—that's the responsible server.
Real-world example of how a request flows through a consistent hashing system
Scenario: Distributed Cache (like Memcached cluster)
You have 3 cache servers with 3 virtual nodes each:
Hash Ring (0 to 999 for simplicity):
Position 045 → Server A (vnode 0)
Position 123 → Server B (vnode 0)
Position 234 → Server C (vnode 0)
Position 456 → Server A (vnode 1)
Position 567 → Server B (vnode 1)
Position 678 → Server C (vnode 1)
Position 789 → Server A (vnode 2)
Position 890 → Server B (vnode 2)
Position 912 → Server C (vnode 2)
Request comes in:
A user requests: GET user:12345:profile
Step-by-step:
Hash the key:
hash("user:12345:profile") → 500Find position on ring: Looking at position 500, search clockwise for the next server:
... 456 (Server A) < 500 < 567 (Server B) ...
The next position clockwise is 567 → Server B
- Route to Server B: Request goes to Server B (192.168.1.20):
Client → Load Balancer → Server B
Server B handles it
If data exists: return from cache
If miss: fetch from database, cache it, return to client
Another request:
GET user:99999:profile
hash("user:99999:profile") → 800Next position clockwise: 890 → Server B
Route to Server B again
Third request:
GET user:55555:profile
hash("user:55555:profile") → 100Next position clockwise: 123 → Server B
Route to Server B
Fourth request:
GET product:88888:details
hash("product:88888:details") → 950Next position clockwise: wrap around to 045 → Server A
Route to Server A
What happens when Server C fails?
Ring becomes:
Position 045 → Server A
Position 123 → Server B
Position 456 → Server A
Position 567 → Server B
Position 789 → Server A
Position 890 → Server B
(Server C's positions removed)
Keys that were on Server C (positions 234, 678, 912) now redistribute:
Keys near 234 → go to Server A (position 456)
Keys near 678 → go to Server A (position 789)
Keys near 912 → go to Server A (position 045)
Only ~33% of keys are remapped (those that were on Server C), not the entire dataset!