The 20-Hour Principle: A Rigorous Framework for Mastering Advanced Data Structures and Algorithms

The Myth We Were Sold
For decades, the prevailing cultural narrative around skill acquisition has been anchored to a single, intimidating figure: 10,000 hours. Popularized by Malcolm Gladwell's Outliers and rooted in Anders Ericsson's research on deliberate practice among elite performers, the number became shorthand for mastery — and, inadvertently, a reason for paralysis. If true expertise demands a decade of sustained effort, why begin at all?
The answer, as researcher and author Josh Kaufman articulated in his 2013 work The First 20 Hours, is that Gladwell and the popular imagination fundamentally misread Ericsson's finding. Ericsson was studying world-class, competitive expertise — the kind that separates the top 0.1% of a field from the top 1%. He was not studying functional proficiency. He was not studying the point at which a skill becomes genuinely useful.
Kaufman's insight was precise: the learning curve is not linear. It is logarithmic. The transition from complete ignorance to remarkable competence happens almost entirely within the first hours of structured, intentional practice. After that, additional hours yield diminishing marginal returns — refining rather than building.
Twenty hours of deliberate effort, Kaufman argued, is sufficient to move from zero to good enough to be dangerous in nearly any skill domain.
The Architecture of the 20-Hour Rule
The theory is not simply a motivational assertion. It rests on four operational principles that Kaufman derived from cognitive science and learning theory:
Deconstruct the Skill : A skill is rarely atomic. "Playing chess" is actually dozens of sub-skills: piece valuation, endgame technique, opening theory, tactical pattern recognition. The first obligation of the learner is to decompose the target competency into its constituent parts, then identify which subset accounts for the majority of practical utility — a direct application of the Pareto principle to cognition.
Learn Enough to Self-Correct : Traditional pedagogy encourages passive reception: absorb instruction, then apply it. Kaufman inverts this. The learner should acquire just enough foundational knowledge to recognize when their own output is wrong — not to achieve comprehensive theoretical understanding, but to build a feedback loop. This is the difference between studying a chess book for six months and playing badly-corrected games from day one.
Remove Barriers to Practice : Friction is the enemy of deliberate practice. Kaufman identifies environmental and psychological barriers — a disorganized workspace, an unclear practice structure, the anxiety of beginning — as the primary obstacles to effective early learning, not the complexity of the skill itself. Eliminating these barriers is a precondition for the twenty hours to be genuinely productive.
Practice for at Least 20 Hours : This is the most psychologically demanding principle. The beginning of skill acquisition is characterized by conscious incompetence — you are aware of what you do not know, and this awareness is deeply uncomfortable. Most learners abandon the process here, misinterpreting early difficulty as a signal of unsuitability rather than what it actually is: the most productive phase of learning. Twenty hours is approximately the threshold at which this discomfort transitions into functional fluency.
Why Advanced DSA Is the Perfect Candidate
The intersection of Kaufman's framework with technical interview preparation is not coincidental. Advanced Data Structures and Algorithms — the domain assessed by FAANG and top-tier product companies — exhibits precisely the structural properties that make the 20-hour rule maximally applicable.
The Domain Is Pattern-Dense, Not Knowledge-Dense
This distinction is critical. A knowledge-dense domain — say, the history of the Ottoman Empire — requires the accumulation of vast, largely non-transferable factual content. Progress is essentially linear with time invested.
Advanced DSA, by contrast, is pattern-dense. There are approximately twenty to thirty foundational algorithmic patterns — sliding window, monotonic stack, union-find, bitmask DP, Dijkstra's shortest path, and others — and the overwhelming majority of interview problems at elite companies are instantiations of these patterns. The learner who has deeply internalized these patterns possesses a combinatorial advantage: each new problem is not a novel challenge but a recognition exercise.
This is precisely the structure that rewards concentrated, structured effort over diffuse accumulation.
The Feedback Loop Is Immediate and Unambiguous
Effective learning requires rapid feedback. In many domains — leadership, writing, relationship management — feedback is delayed, subjective, and difficult to interpret. In algorithmic problem-solving, the feedback is binary and instantaneous: the solution is correct, or it is not. The time complexity is optimal, or it is not.
This property is not merely convenient — it is transformative. It means the learner can self-correct at high velocity, compressing what might otherwise require months of guided instruction into concentrated hours of deliberate practice.
The Skill Transfers Non-Linearly
Mastery of a graph traversal algorithm does not merely prepare you for graph problems. It develops the recursive intuition that underpins dynamic programming. It deepens your understanding of state-space search, which informs backtracking. It sharpens your complexity analysis, which benefits every problem you subsequently encounter.
This cross-pattern transfer means that the effective value of each hour spent on advanced DSA compounds. The twentieth hour is substantially more productive than the first — not because you are working harder, but because your conceptual infrastructure is richer.
The 20-Hour Advanced DSA Sprint: Structural Design
Applying Kaufman's four principles to advanced DSA produces a specific, non-arbitrary structure. What follows is not a collection of arbitrary topics — it is a deliberately sequenced architecture, designed to maximize pattern coverage and cross-domain transfer within a twenty-hour constraint.
Deconstruction: The Twenty Core Patterns
The full landscape of advanced DSA, when rigorously deconstructed, resolves into a tractable set of patterns. The twenty-hour sprint targets the following, sequenced by dependency:
Hours 1–2: Complexity Reasoning and Array Primitives Before any advanced pattern can be internalized, the learner must possess fluent, not merely correct, complexity analysis. This is not about memorizing that merge sort is O(n log n) — it is about being able to derive that fact from first principles in under sixty seconds. Alongside this, the two core array patterns — sliding window and two-pointer — establish the template for spatial reasoning across a sequence that recurs throughout the curriculum.
Hours 3–4: Linked Structures and Stack Invariants Floyd's cycle detection algorithm is not merely a linked list trick. It is an introduction to the two-pointer paradigm applied to implicit graphs — a conceptual bridge that pays dividends in graph theory and dynamic programming. The monotonic stack pattern, meanwhile, introduces the learner to invariant maintenance: the discipline of designing data structures that preserve a specific property across every operation. This discipline is foundational to segment trees, heaps, and interval problems.
Hours 5–7: Tree Recursion and Hierarchical Decomposition Trees are the domain where recursive thinking transitions from technique to intuition. The learner who has solved sufficient tree problems does not consciously think "I will apply a recursive decomposition here" — they perceive the tree's structure and the solution manifests naturally. This hours bloc also introduces the Trie and Segment Tree, which extend the tree abstraction into string processing and range query domains respectively.
Hours 8–9: Heap-Based Optimization and Greedy Reasoning The heap is one of the most frequently underestimated data structures in interview preparation. Its power lies not in any single application but in its general utility as a dynamic ordering mechanism — whenever a problem requires maintaining the k largest, k smallest, or a running median across a stream of data, the heap is almost certainly the optimal instrument. The adjacent topic of greedy algorithms demands a different cognitive mode: rather than exhaustive exploration, the learner must develop the discipline of proving local optimality implies global optimality — a reasoning pattern that, once internalized, is immediately recognizable across a wide problem class.
Hours 10–12: Graph Algorithms and Structural Reasoning Graph theory constitutes the single largest domain in the advanced DSA curriculum, and for good reason: it is the most general framework for reasoning about relationships, dependencies, and connectivity. The three-hour allocation covers BFS/DFS and topological ordering (Hour 10), shortest path algorithms from Dijkstra through Bellman-Ford (Hour 11), and advanced structural algorithms including Tarjan's bridge-finding and the Union-Find data structure (Hour 12). The sequencing matters: each hour builds directly on the abstractions established in the prior one.
Hours 13–15: Dynamic Programming — The Summit Dynamic programming is, by consensus among competitive programmers and interview coaches, the most cognitively demanding topic in the advanced DSA curriculum. It is also the most frequently decisive in top-tier interviews. The three-hour allocation is not arbitrary — it reflects the domain's genuine complexity and the number of conceptual layers that must be constructed.
Hour 13 establishes the two fundamental DP paradigms — memoization and tabulation — and applies them to one-dimensional state spaces. Hour 14 extends the state space to two dimensions and introduces interval DP, where the insight that a subproblem's boundaries can themselves be the state variables represents a significant conceptual leap. Hour 15 reaches the frontier: knapsack variations, bitmask DP for combinatorial state spaces, and DP on trees — the techniques that separate candidates who pass technical screens from those who excel.
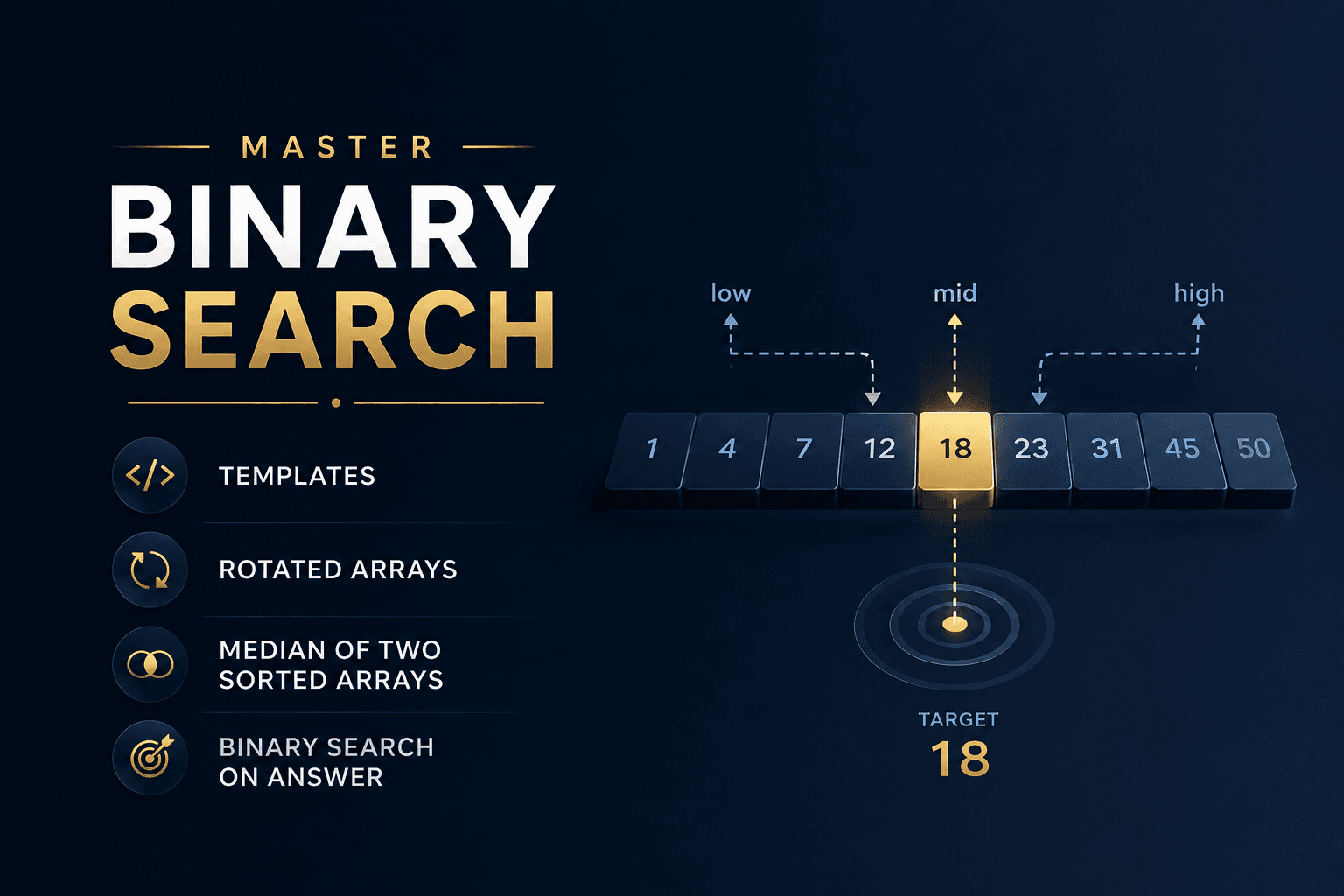
Hours 16–17: Binary Search as a Universal Tool The cultural framing of binary search as a search algorithm is one of the great pedagogical failures in computer science education. Binary search is, more accurately, a general-purpose technique for eliminating half the solution space at each step — applicable wherever the answer space is monotonic. The canonical insight — that one can binary search not just on a sorted array but on the answer itself — unlocks an entire class of optimization problems, from allocating bandwidth to scheduling resources, that would otherwise appear intractable.
Hours 18–19: Backtracking and String Algorithms Backtracking introduces constraint propagation — the discipline of abandoning a partial solution the moment it is provably non-extensible to a valid complete solution. This pruning mentality has direct applications in NP-hard problem approximation and branch-and-bound optimization. The KMP and Rabin-Karp string matching algorithms, meanwhile, demonstrate how mathematical structure — the failure function and rolling hash respectively — can reduce what naively appears to be an O(n·m) problem to O(n+m). This is algorithmic elegance in its purest form.
Hour 20: Synthesis Under Constraint The final hour is a mock interview under competitive conditions. Two unseen problems. A strict time constraint. No external reference. This is not review — it is transfer assessment: the measure of whether the patterns learned in hours one through nineteen have been sufficiently internalized to be retrieved and recombined under pressure. It is also the only honest proxy for the actual interview environment.

The territory has been mapped. The patterns are finite. The clock starts when you decide it does. The interactive tracker — with every hour, every topic, and your progress saved automatically — is live.
Open the 20-Hour DSA Tracker and check off Hour 1 today.
On the Misconception of Comprehensiveness
A sophisticated objection to the 20-hour framework is this: the domain of advanced DSA is too vast to be meaningfully covered in twenty hours. There are entire subfields — computational geometry, network flow, advanced number theory — that the sprint does not touch.
This objection is correct and irrelevant.
The sprint is not designed to produce encyclopedic coverage. It is designed to produce functional interview readiness at top-tier companies. The patterns covered in this curriculum account for the substantial majority of what appears in technical screens at Google, Meta, Apple, Amazon, and Microsoft. The remaining patterns — the long tail of exotic algorithmic techniques — appear rarely enough that the expected return on learning them within a twenty-hour constraint is negative.
More fundamentally, the learner who has genuinely internalized the patterns in this sprint has developed the cognitive infrastructure to acquire those remaining techniques rapidly when needed. Foundational fluency enables targeted expansion. The converse is not true.
The Discipline of Beginning
Josh Kaufman's most profound observation was not about learning curves or logarithmic returns. It was about the psychology of beginning.
The greatest barrier to skill acquisition is not difficulty. It is the anticipation of difficulty — the friction of starting, the discomfort of early incompetence, the temptation to prepare to learn rather than to learn.
Twenty hours is a psychologically tractable commitment. It is concrete, bounded, and achievable within a single week of focused effort — or several weeks at a sustainable pace. It does not demand the suspension of ordinary life. It demands only the discipline to show up, to practice deliberately, and to resist the seductive inertia of indefinite preparation.
The advanced DSA curriculum is demanding. The problems are hard. The patterns are non-obvious. The pressure of technical interviews is real.
But the territory has been mapped. The patterns are finite. The path is twenty hours long.
Begin.
Yashraj writes about system design, frontend engineering, and the craft of technical learning at viewport.blog. The interactive 20-hour DSA tracker referenced in this article is available as a learning tool.