Big-O Complexity: The Complete Guide Every Developer Must Know
Every developer writes code. But not every developer understands why their code slows to a crawl on large inputs — or why their interviewer winces at a nested loop. Big-O notation is the language that bridges that gap. It lets you reason about performance before you ever run a benchmark.
This guide covers everything: the six essential complexities, amortized analysis, space trade-offs, and five classic algorithm derivations from scratch. By the end, you'll be able to look at any code and derive its complexity — not just recite it from memory.
What Big-O Actually Means
Big-O is an upper bound on how an algorithm's resource usage grows as input size n increases. Formally, f(n) = O(g(n)) means there exist constants c > 0 and n₀ such that f(n) ≤ c·g(n) for all n ≥ n₀.
In plain English: past some input size, f never outgrows g by more than a constant factor.
There are three related notations worth knowing:
O (Big-O) — upper bound (worst case)
Ω (Omega) — lower bound (best case)
Θ (Theta) — tight bound (both upper and lower)
In practice, when an interviewer asks "what's the complexity?", they almost always mean Big-O worst case.
Two rules make simplification mechanical:
3n + 5 → O(n) (drop the constant)
n² + n → O(n²) (drop the lower-order term)
n³ + 2ⁿ → O(2ⁿ) (keep the dominant term)
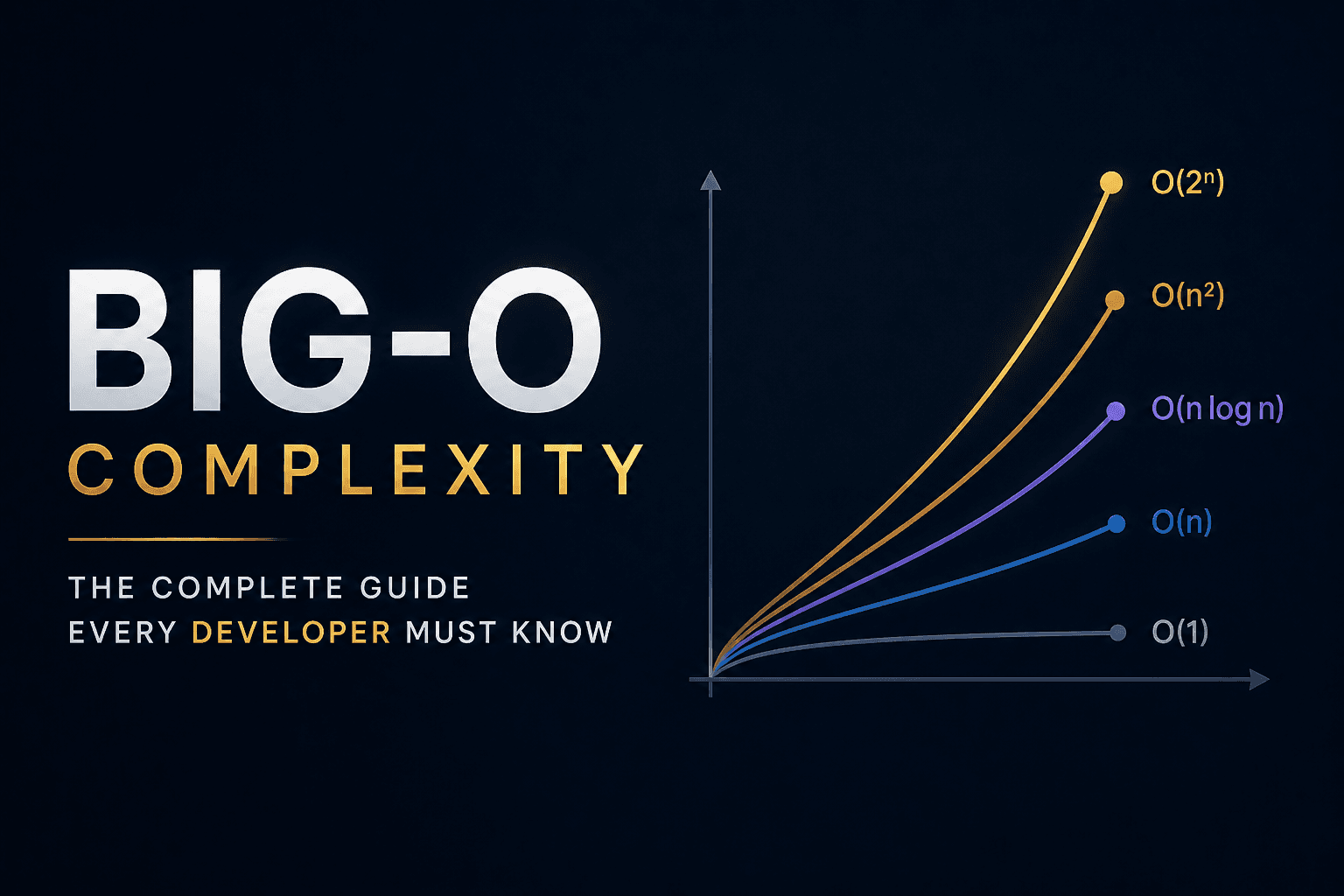
The Six Complexities You Must Know
O(1) — Constant Time
Execution time does not change regardless of input size. No loops, no recursion over the input — just direct access or a fixed number of operations.
def get_first(arr):
return arr[0] # O(1) — direct index
Real examples: array index access, hash map get(), stack push(), checking if a number is even.
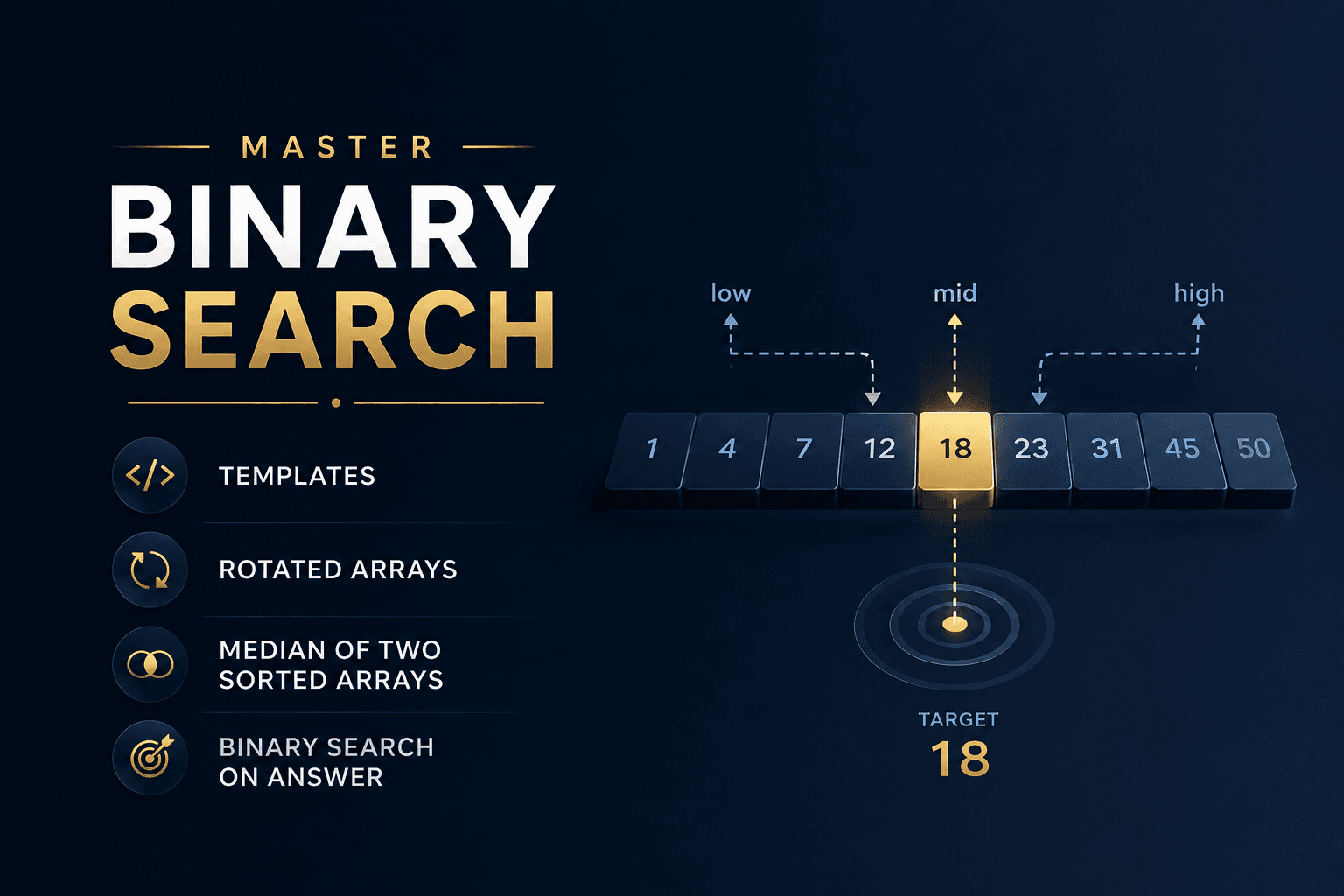
O(log n) — Logarithmic Time
Each step cuts the remaining work in half (or by some constant fraction). If n doubles, the cost increases by just one step. This is the reward for exploiting sorted or hierarchical structure.
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target: return mid
elif arr[mid] < target: left = mid + 1
else: right = mid - 1
return -1
After k iterations the search space is n / 2ᵏ. Setting that to 1 gives k = log₂(n).
Real examples: binary search, BST lookup, heap insert, finding a name in a phone book.
O(n) — Linear Time
One unit of work per element. A single loop over the input, with O(1) work per iteration.
def find_max(arr):
max_val = arr[0]
for x in arr: # visits each element once
if x > max_val:
max_val = x
return max_val
Real examples: linear search, array sum, counting frequencies, two-pointer scan, most string problems.
O(n log n) — Linearithmic Time
This is the complexity of divide-and-conquer algorithms. You split the input (log n levels deep) and do O(n) work at each level. It's the lower bound for comparison-based sorting — you cannot sort faster than this using only comparisons.
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right) # O(n) merge at each level
Recurrence: T(n) = 2T(n/2) + O(n) → O(n log n) by the Master Theorem.
Real examples: merge sort, heap sort, average-case quicksort, building a balanced BST from sorted data.
O(n²) — Quadratic Time
Every element is compared against every other element. Nested loops where both bounds depend on n. Fine for small inputs (n < 1000), increasingly painful beyond that.
def bubble_sort(arr):
for i in range(len(arr) - 1):
for j in range(len(arr) - 1 - i):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
Total comparisons: (n-1) + (n-2) + ... + 1 = n(n-1)/2 = O(n²).
Real examples: bubble sort, insertion sort, selection sort, brute-force pair finding, naive duplicate detection.
O(2ⁿ) — Exponential Time
Each new element doubles the work. The call tree is a full binary tree of depth n — 2ⁿ leaves, 2ⁿ total nodes. Becomes infeasible past roughly n = 30–40.
def fib(n):
if n <= 1: return n
return fib(n-1) + fib(n-2) # two recursive calls per call
Real examples: naive Fibonacci, generating all subsets (power set), naive travelling salesman, recursive backtracking without pruning.
Amortized Analysis: When Worst Case Lies
Amortized analysis gives you the average cost per operation over a sequence of operations — even when individual operations have wildly different costs. Three methods exist: aggregate analysis, the accounting method, and the potential method. The aggregate method is most intuitive for interviews.
Dynamic Array (ArrayList) Resizing
This trips up a lot of people. Each append is O(1) — until the array is full, at which point it doubles and copies everything: an O(n) operation. So why do we say append is O(1) amortized?
Count the total copies across all doublings for n appends:
Array sizes at each doubling: 1 → 2 → 4 → 8 → ... → n
Copies performed at each step: 1 + 2 + 4 + 8 + ... + n/2
Sum = n - 1 (geometric series)
n - 1 total copies across n appends = roughly 1 copy per append. Spread evenly: O(1) amortized.
The intuition: every element was copied at most twice in its lifetime — once when inserted, and once when the array was smaller. Since each element "pays" a constant amount, the total work is O(n) for n appends.
Two-Pointer: Why It's O(n) Not O(n²)
Classic confusion: two pointers iterating through an array looks like two nested loops. It's not.
def two_sum_sorted(arr, target):
left, right = 0, len(arr) - 1
while left < right:
s = arr[left] + arr[right]
if s == target: return (left, right)
elif s < target: left += 1
else: right -= 1
return None
left only ever moves right. right only ever moves left. Together they take at most n total steps — not n steps each. The loop terminates when they meet. Total work: O(n).
The same reasoning applies to sliding window algorithms: even if there's a while loop inside a for loop, each element enters the window once and leaves once. Total events = 2n = O(n).
Space Complexity and Trade-offs
Space complexity counts the extra memory your algorithm allocates — stack frames from recursion included. The input itself is usually excluded (unless asked for auxiliary space).
The Four Common Space Complexities
O(1) — in-place: Only a fixed number of variables regardless of input. Two-pointer, iterative approaches, in-place sorting.
O(log n) — recursive stack: Balanced recursion depth. Binary search (recursive), quicksort stack frames (average case), BST traversal.
O(n) — linear memory: Hash map for frequency counting, BFS queue, auxiliary array for merge sort's merge step, recursion depth up to n (linked list recursion).
O(n²) — quadratic memory: 2D DP table (edit distance, LCS), adjacency matrix for dense graphs, storing all pairs.
Classic Time–Space Trade-offs
Recognizing these patterns is a high-value interview skill:
PROBLEM: Two Sum
Brute force: O(n²) time, O(1) space — nested loop, no extra memory
Hash map: O(n) time, O(n) space — store complements as you scan
PROBLEM: Fibonacci(n)
Naive recursion: O(2ⁿ) time, O(n) stack — exponential call tree
Memoization: O(n) time, O(n) space — cache each subproblem once
Bottom-up DP: O(n) time, O(n) space — tabulation, no stack
Space-optimized: O(n) time, O(1) space — only keep last two values
The general pattern: you trade memory for speed. A hash map turns an O(n²) search into O(n) by paying O(n) space. Always state both dimensions when answering complexity questions.
Deriving 5 Classic Algorithms from Scratch
Don't just memorize the answers. Derive them. Here's how.
1. Binary Search — O(log n) time, O(1) space
Each iteration halves the search space: n → n/2 → n/4 → ... → 1. After k iterations: n / 2ᵏ = 1, so k = log₂(n). Each iteration does O(1) work. Total: O(log n). The iterative version uses O(1) space; the recursive version uses O(log n) stack frames.
2. Merge Sort — O(n log n) time, O(n) space
Recurrence: T(n) = 2T(n/2) + O(n). Visualize as a tree: log₂(n) levels of recursion, and at each level the merge steps together touch every element exactly once → O(n) work per level. Total: O(n) × log n levels = O(n log n). Space: O(n) for the merge buffer, O(log n) for the call stack — dominated by O(n).
Master Theorem check: a=2, b=2, f(n)=n. log_b(a) = 1. Since f(n) = Θ(n¹), Case 2 applies: T(n) = Θ(n log n). ✓
3. BFS / DFS on a Graph — O(V + E)
Derive it element by element. Each vertex is visited exactly once → O(V) for vertex processing. For each vertex, we scan its adjacency list. Across all vertices, the total edges scanned equals E (each edge seen once in a directed graph, twice in undirected). Total: O(V) + O(E) = O(V + E). Space: O(V) for the visited set plus O(V) for the queue/stack.
Insight: for a dense graph where E ≈ V², this becomes O(V²). For a sparse graph where E ≈ V, it's O(V). Always parameterize by both V and E.
4. Bubble Sort — O(n²) time, O(1) space
Count the comparisons exactly. Pass 1 does n-1 comparisons, pass 2 does n-2, ..., pass n-1 does 1. Total: (n-1) + (n-2) + ... + 1 = n(n-1)/2 = (n² - n)/2. Drop the constant and lower-order term: O(n²). No extra memory beyond loop variables: O(1) space.
5. Naive Recursive Fibonacci — O(2ⁿ) time, O(n) space
Draw the call tree for fib(5). Each call spawns two more calls. The tree has depth n (deepest branch: n → n-1 → ... → 0). A full binary tree of depth n has at most 2ⁿ nodes. Each node does O(1) work. Total: O(2ⁿ). The deepest recursion stack is n frames deep: O(n) space.
The fix: memoize. Once you cache fib(k), each of the n distinct subproblems is computed exactly once → O(n) time. The duplicate calls (that caused fib(2) to be recomputed three times) simply return the cached value in O(1).
5 Practice Problems
Work through each one before reading the answer.
Problem 1
def has_duplicate(arr):
seen = set()
for x in arr:
if x in seen:
return True
seen.add(x)
return False
What are the time and space complexities?
Answer
Time: O(n) | Space: O(n)
The loop runs at most n times. Each in seen and seen.add is O(1) amortized (hash set operations). Worst case: no duplicates, full scan → O(n). The seen set stores at most n elements → O(n) space. Early exit doesn't improve Big-O — worst-case analysis doesn't assume luck.
Problem 2
def find_pair(arr, target): # arr is sorted
left, right = 0, len(arr) - 1
while left < right:
s = arr[left] + arr[right]
if s == target: return (left, right)
elif s < target: left += 1
else: right -= 1
return None
What is the time complexity? Justify it.
Answer
Time: O(n) | Space: O(1)
left only ever increments. right only ever decrements. Neither pointer ever reverses. Together they can take at most n total steps before left >= right. The loop cannot run more than n iterations — not n iterations each. No extra data structures → O(1) space.
Problem 3
def count_bits(n):
count = 0
while n > 0:
count += n & 1
n >>= 1
return count
What is the tight complexity (use Θ notation)?
Answer
Time: Θ(log n) | Space: O(1)
Each iteration right-shifts n by one bit, equivalent to integer division by 2. The loop runs until n becomes 0. The number of bits in n is ⌊log₂(n)⌋ + 1. So iterations = number of bits = Θ(log n). This is tight — every bit must be examined regardless of their values. Only count and n are stored → O(1) space.
Problem 4
def nested(arr):
result = []
for i in range(len(arr)):
for j in range(len(arr)):
result.append(arr[i] + arr[j])
return result
# Claimed: O(n²) time, O(1) space. Is this correct?
Answer
Time: O(n²) ✓ | Space: O(n²) — NOT O(1)!
The time analysis is correct: n × n iterations = O(n²). But the space claim is wrong. result is built up and returned — it holds one entry per (i, j) pair. That's n × n = n² entries. The output list alone takes O(n²) space.
This is one of the most common complexity mistakes in interviews. Always account for output space when the function allocates and returns a data structure. O(1) space only applies when computing a scalar result or modifying data in-place.
Problem 5
def mystery(arr, lo, hi):
if lo >= hi: return
mid = (lo + hi) // 2
mystery(arr, lo, mid)
mystery(arr, mid+1, hi)
arr[lo], arr[hi] = arr[hi], arr[lo] # O(1) work
# mystery(arr, 0, len(arr)-1)
Derive the complexity from the recurrence.
Answer
Time: O(n) | Space: O(log n) stack
Recurrence: T(n) = 2T(n/2) + O(1).
Master Theorem: a=2, b=2, f(n)=1. log_b(a) = log₂(2) = 1. Compare f(n) = 1 against n^(log_b a) = n¹ = n. Since f(n) = O(n^(1-ε)) for ε=1, Case 1 applies: T(n) = Θ(n).
Intuitively: the recursion tree is a full binary tree of depth log n, with n leaves (base cases) and 2n - 1 total nodes. Each node does O(1) work → O(n) total. The recursion stack depth = tree height = O(log n).
The Interview Cheat Sheet
O(1) → direct access, hash map ops, math formula
O(log n) → search space halving, binary search, balanced tree ops
O(n) → single loop, two pointers, sliding window
O(n log n) → divide and conquer, comparison sort lower bound
O(n²) → nested loops over same input, brute-force pairs
O(2ⁿ) → power set, naive recursion with two branches per call
Time–space: HashMap converts O(n²) brute force → O(n) scan
Amortized: Dynamic array append = O(1), not O(n)
Recursion: Call depth = space. DFS tree of height h = O(h) stack
Always: State BOTH time and space. O(n²) time, O(n²) space ≠ O(n²) time, O(1) space
Big-O is a tool for reasoning, not memorization. Once you can look at a loop and count its iterations, look at a recursion tree and count its nodes, and recognize when amortized costs smooth out spikes — the complexities follow naturally.
Derive, don't recite.